الكل يقيس مخرجات الذكاء الاصطناعي التوليدي لا أحد يقيس ما تفعله بالتفكير
الكل يقيس مخرجات الذكاء الاصطناعي التوليدي وأشهرها النصوص، ولكن من يقيس التفاعل بين المستخدم والمخرجات كفعل القراءة مثلاً؟ بل هل يوجد إطار جامع؟
ولبناء ذلك على أساس ثابت، لنثبت أن هناك علاقة بين مخرجات الذكاء الاصطناعي التوليدي وبين التفكير الإنساني ونصف هذه العلاقة. اخترت دراسةGerlich من العام الماضي 2025، وقد شملت 666 مشاركاً مقسمين لفئات عمرية مختلفة، أظهرت أنه كلما زاد استخدام أدوات الذكاء الاصطناعي ضعفت مهارات التفكير النقدي للفرد. وهذه علاقة تبادلية سلبية حيث تُفرط هذه الأنظمة في إسناد الجهد الإدراكي إلى المستخدم.
وبذلك نفهم أن المخرجات تؤثر على المستخدم بشكل سلبي. فيأتي السؤال: كيف تقوم المؤسسات التي تبني وتتبنى الذكاء الاصطناعي برؤية هذه العلاقة أثناء بناء واختبار منتجاتها؟
الجواب هو لا. وهذه فجوة بين ما يجري وما يظهر في المؤشرات الحالية.
هذا العام ألبسته المملكة العربية السعودية صفة عام الذكاء الاصطناعي. وتبني القطاعات الحكومية والتقنية والمالية والصحية والتعليمية وغيرها متسارع الوتيرة مواكباً لما يحدث عالمياً. فالمملكة هي الأولى عربياً في تطوير نماذج الذكاء الاصطناعي، والأولى عالمياً في تبني القطاع العام له.
وهذه الرشاقة الحكومية تستوجب حوكمة ابتكارية سبّاقة لا ناقلة.
وعندما ندخل هذا النطاق تتغير المقاييس. وربما تقول: حسناً، هناك ضرر، ولكن كم حجمه وهل هو مؤثر؟ وهذا سؤال مشروع.
ولمساعدتك على تخيّل التأثير، فإن 1 من كل 3 مستخدمين للذكاء الاصطناعي التوليدي قُدِّمت له إجابات مضللة من نظام نجح في كل اختبارات الدقة، وهذا من دراسة Deloitte نُشرت في يونيو 2025.
التأثير كبير ويتراكم بهدوء. والأطر والمقاييس الحالية لا تراه. وإذا وصل إلى المؤشرات فقد تشكّل منذ فترة طويلة.
وقبل أن نشرع في الحلول والاستيراد المعرفي لنفكر قليلاً، لأننا اليوم في نقطة زمنية نستطيع فيها أن نفكر ونسبق بدلاً من أن نستورد وننسخ.
لنبدأ بهذا السؤال البسيط: لماذا يحدث كل هذا دون أن نراه ونقيسه؟
ولنجيب على هذا السؤال أريدك أن ترى تجربة الذكاء الاصطناعي التوليدي كنظام، وبالتحديد الفرق بين الأنظمة الحتمية والأنظمة الاحتمالية.
المنظومات الحتمية هي الأنظمة التي تتصرف بالطريقة ذاتها في كل مرة. فالضغط على زر في استبانة دائماً ما ينجم عنه إجراء معين من خيارات محددة مسبقاً، مثل قبول أو تعديل أو رفض، وما سيظهر للمستخدم هو دائماً أحدها لا رابع لها.
لكن الذكاء الاصطناعي التوليدي لا يعمل بهذا الشكل.
فهو نظام غير حتمي ينتهج نمذجة احتمالية، بمعنى أن المخرجات حتى عند تطابق ظروف الاستخدام تنتج مخرجات مختلفة دائماً. نفس السؤال حتى عند التطابق يُنتج إجابتين مختلفتين. إذن التجربة لا يمكن إعادتها. وأساس المنهجية العلمية هو قابلية الاستنساخ.
الآن لنركّب القطع: لأي نوع من المنظومات صُمِّمت أدوات التقييم والقياس التي تستخدمها؟
الجواب هو الأنظمة الحتمية.
فعندما لا يمكن إعادة التجربة، سينهار منطقياً معها كل إطار لم يُصنع لهذا النوع من الأنظمة. وهذا ما أسمّيه العطب البنيوي.
الأدوات التي نمتلكها اليوم صُمِّمت للنوع الأول. ونحن ننشر النوع الثاني على نطاق مؤسسي واسع مع أطر صُمِّمت للأنظمة الحتمية.
وهذا يعني أننا لسنا مسؤولين عمّا ستكون عليه المخرجات، عكس الأنظمة الحتمية، إنما مسؤولين عمّا ستفعله المخرجات بالمستخدم الذي يتلقاها. المحتوى يُعالَج من قِبَل المستخدم ونحن لا نعرف ماذا حدث أثناء هذه المعالجة. وهذه مسؤولية تصميمية مختلفة تماماً وتستلزم أدوات مختلفة.
وربما الآن تسأل: ما الذي يعنيه هذا عملياً على أرض الواقع؟
أهم ما يجري في أي تفاعل مع الذكاء الاصطناعي التوليدي يحدث أثناءه، أي في الحالة الإدراكية للمستخدم في تلك اللحظة بعينها مع المخرج. فالثقة تتشكل مباشرةً والتفاعل ثنائي الاتجاه. فعندما تأتي استبانة الرضا تكون اللحظة قد مضت.
أنت كمن يرى مشهداً واحداً من فيلم متحرك دون أن يعرف أنه متحرك.
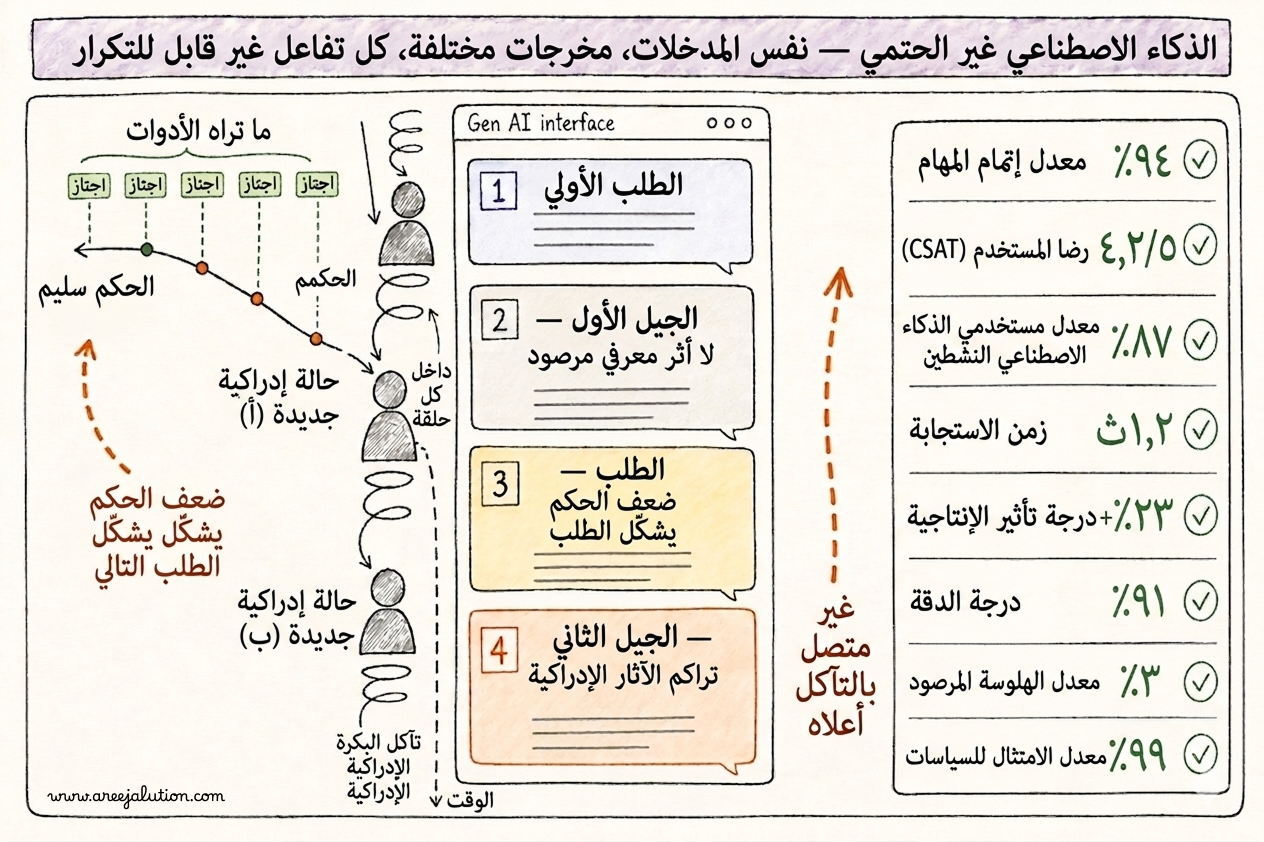
لنشرح هذا بمثالين من تجربتي العملية.
في دراسة ميدانية مع باحثي تصميم يستخدمون وكيل ذكاء اصطناعي لتلخيص البحوث، أحب المستخدمون الملخصات في البداية. تصفّحوا، أومأوا، قبلوا. حين قابلتهم لاحقاً أفضوا إليّ بأنهم أحياناً اعتقدوا أن الهلوسات كانت حقائق، فقد كان كل شيء مقنعاً. وبعد النقاش مع الفريق استنتجنا أن الخطأ لم يكن في النموذج بل في المنهج.
وهذا الانزياح في الثقة، أي التحوّل التدريجي من الشك الصحي إلى القبول غير النقدي، رأيته نوعياً ولم يكن لديّ أداة لرصده كمياً.
وفي مهمة بحثية أخرى، أدرت جلسات استشراف مستقبلي مع فرق تقنية وإدارة أعمال باستخدام نماذج لغوية. ما كان مهماً لم يكن الطلب أو المخرج، بل كانت اللحظة التي توقف فيها كل المشاركين بلا استثناء عن المراجعة وعن التشكيك. لم يكن رضا. كان انفصالاً معرفياً. فالمخرجات بدت حاسمة ونهائية بسبب الواجهة التي أظهرتها كقرينة قطعية.
كل المقاييس الحالية من توقيت المهام وعدد الأخطاء ودرجات الرضا قد أغفلت هذه اللحظة.
ولم أذكر لك هاتين التجربتين عبثاً. ثمة نمط مشترك بينهما تكشفه دراسة Shojaee وزملائه عام 2025، التي أثبتت أن مخرجات GPT-4 نالت تقييماً أفضل من إجابات الخبراء البشريين ليس بسبب الدقة، بل بسبب الانسجام والنبرة الواثقة. وحتى الباحثون المتخصصون في الذكاء الاصطناعي انطلى عليهم بسبب ظاهرة الانحياز المعرفي.
الطلاقة أدّت دور الصواب. المخرجات لم تحتج أن تكون صحيحة لتبدو ذات سلطة. وحين يبدو شيء ما سلطوياً تتوقف الجهود المعرفية للتقييم قبل أن تبدأ.
ما تشترك فيه الحالتان يكشف نقطتَي عمى:
أولاً: الثقة تتشكّل أو تتصلّب في كل تفاعل بصرف النظر عن صحة المخرجات. المستخدمون الذين يثقون بالنظام يتوقفون عن التشكيك فيه. هذا التحوّل غير مرئي حالياً لأطر القياس والحوكمة.
ثانياً: الواجهة هي الوسيط الذي إما يُيسّر أو يُعسّر عملية التقييم والتفكير عند المستخدم. معظم واجهات الذكاء الاصطناعي تُعسّر هذه العملية. فالمخرجات تبدو منتهية والمستخدم يقبل ذلك. وأطر القياس قاست المعاملة وأغفلت التفكير، هذا لم يُقَس.
ولا تظنّن أن نقطة العمى الثانية هي مشكلة قياس وحوكمة فحسب، بل هي ذات تبعات.
التفكير ليس عملية خاملة بل عملية ذات تغذية راجعة. فعندما يقبل المستخدم المخرجات دون تقييم فإن هذا القبول سيشكّل:
كيف سيكتب البرومبتات القادمة
تفاعله مع الواجهة
القرارات التي يتخذها بمساعدة المخرجات
ولذا فإن هذا المسار يؤدي إلى تدهور عملية الحكم وبالتالي إلى تدهور المخرج نفسه. فالواجهة لم تترك مساحة للمستخدم ليتوقف ويحكم بموضوعية. وكلما طالت المحادثة الواحدة مع الوكيل تدهورت الجودة.
وهذه الظاهرة أسمّيها تآكل البكرة.
وهذه البكرة تدور انشوطياً حالياً في مؤسستك بشكل لا مرئي داخل كل وكيل وعند كل تفاعل.
لذا إن كان الموظفون يستخدمون الذكاء الاصطناعي التوليدي لتلخيص أبحاث أو إنشاء آراء أو توليد توصيات، والواجهة تُنتج قبولاً لا تقييماً، فأنتم لا تحصلون على العائد ROI الذي تعتقدون.
ما تحصلون عليه: السرعة. ما تخسرون: جودة الحكم، وسلامة القرار، وبمرور الوقت الذكاء الجمعي المؤسسي.
لا يظهر هذا في الربع القادم. هو يتراكم.
وهذا يحتاج إلى أدوات مختلفة، وليست بدائل بل امتدادات إلى الطبقة التي لا تستطيع الأدوات الحالية رؤيتها:
دلتا الثقة: هل ازدادت الثقة بصورة تدريجية مع كل تفاعل أم توقفت قبل أن تُكتسب؟
العبء الاستيعابي: هل شجّعت الواجهة على الاستيعاب والتدبر أم ألبست المخرجات صفة الحسمية؟
التعمّق والعبور: هل امتلك المستخدمون ما تفاعلوا معه عبر التقييم والتغيير أم تصفّحوه ومضوا؟
هذه ليست مقاييس ناعمة. قد تكون نظرية الآن، لكن حتى في هذا الحال هي إشارات عمّا إذا كان الذكاء الاصطناعي التوليدي يُعزّز الإدراك أم يُوكله للآلة. إن لم تستطع الأطر والمقاييس المستخدمة أن تحسب لها حساباً فهي لا تُغفل تفصيلاً وحسب، بل تُسيء تمثيل قيمة المنتج.
تآكل البكرة لن يبقى حبيس الشاشات.
فهذا التآكل الانشوطي سينتقل على نطاق أوسع حين يُستخدم الذكاء الاصطناعي في الأنظمة المحيطة والمستشعرات والواجهات المكانية وإنترنت الأشياء. فحتى الأماكن العامة وليس فقط نوافذ المحادثات ستصبح مناطق بوساطة ذكاء اصطناعي.
وبذلك تآكل البكرة الذي لا يُقاس اليوم في الشاشات كيف سيُقاس في غرفة، في مبنى، عبر بيئة خدمة كاملة، إن لم تُبنَ الأدوات الآن؟
وهذه أسئلة جوهرية للمملكة في عام الذكاء الاصطناعي.
التقدم لا يُقاس في مدى سرعة التبني وحسب، إنما يكمن في عمق ما نقيس.