Generative AI can produce writing. Who is measuring what it is doing to reading?
Generative AI can now produce writing. Everyone is measuring that.
Who is measuring what it is doing to reading?
Gerlich (2025) studied 666 participants across age groups and found a significant negative correlation between frequent AI tool usage and critical thinking abilities, mediated by increased cognitive offloading. We know this is harmful. But the harder question is whether your organisation can actually see it happening as you deploy. Probably not yet. And that gap between what is occurring and what is visible is exactly where the problem lives.
Because the effect does not announce itself. A Deloitte survey from June 2025 found that one in three generative AI users had already encountered incorrect or misleading answers from a system that scored fine on accuracy tests. The harm accumulates quietly, and by the time it surfaces in your metrics, it has already been forming for months.
So what is going on here?
Let us think about generative AI experience as a system. What type of system is it, do you think?
It is a non-deterministic system. It behaves probabilistically. Different outputs across users, contexts, and moments. Now ask yourself: what type of system were your evaluation tools built for?
Deterministic ones. Systems that behave the same way every time. A button click triggers the same action. The same question returns the same answer. You design the paths, you test whether users can find and follow them, you ship.
AI does not work that way. The same question asked twice produces two different answers. The same prompt given to two different users produces outputs calibrated differently to each context. The experiment cannot be repeated. And when the experiment cannot be repeated, the entire logic of your evaluation breaks with it. Not partially. Structurally.
Which means designing for AI requires something categorically different. You are not designing paths. You are designing conditions. You are not responsible for what the output will be. You are responsible for what the output will do to the person receiving it, regardless of what it contains. That is a completely different design responsibility. And it requires completely different instruments to evaluate.
The instruments we have were built for the first kind of system. We are deploying the second kind at institutional scale.
What that means in practice: the most important thing happening in an AI interaction is happening during it, in the cognitive state of the specific user in that specific moment with that specific output. Trust is forming or locking in real time. By the time you run your satisfaction survey, that moment is gone. And because AI is directional, because the system is moving somewhere based on what came before, a single interaction measurement does not give you a data point. It gives you one frame of a moving picture without telling you the picture is moving.
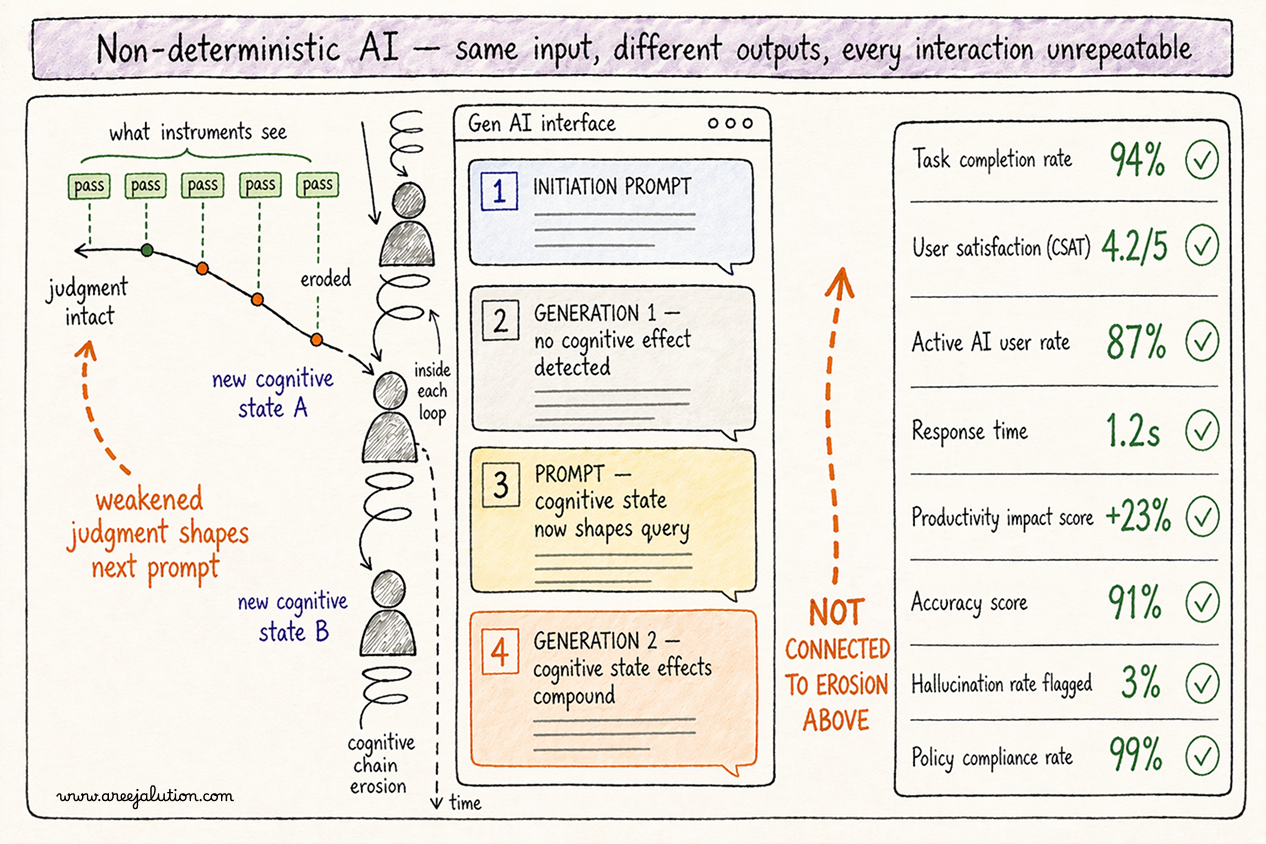
Here is what those invisible layers look like from inside a real engagement.
In a field study with design researchers using a generative AI assistant, users loved the summaries at first. They skimmed, nodded, accepted. When debriefed, they admitted they had misremembered hallucinations as facts. It was not a model error. It was a method error. I had no instrument to detect trust drift, the subtle shift from healthy scepticism to uncritical acceptance over time. In another engagement I facilitated foresight sessions using LLMs to simulate future scenarios. What mattered was not the prompt or the output. It was when participants stopped. Stopped revising. Stopped questioning. I was not witnessing satisfaction. I was witnessing cognitive disengagement. The output felt done. The interface performed finality. These were epistemic moments. Task timing, error counts, satisfaction scores missed them entirely.
There is a reason both cases followed the same pattern. Shojaee et al. (2025) found that GPT-4 outputs were rated more favourably than expert human answers based not on correctness but on coherence and confidence of tone. This held true even among AI researchers. Fluency performs correctness. The output does not need to be right to feel authoritative. And when something feels authoritative, the cognitive work of evaluation stops before it begins.
What both cases share points to the same two blind spots.
First: trust is forming or locking in every interaction, regardless of whether the output was correct. Users who trust the system stop questioning it. That shift is invisible to your current evaluation apparatus.
Second: the interface is deciding how much thinking to hand back to the user. Most AI interfaces hand back none. The output feels finished. The user accepts. You measured the transaction. You missed the thinking.
And here is what makes that second blind spot more than a measurement problem. Thinking is not passive. It feeds back. When a user accepts without evaluating, that acceptance shapes the next prompt they write, the next request they bring to the interface, the next decision they make using AI-generated output. Weakened judgment produces weakened inputs. Weakened inputs produce outputs that further bypass judgment. The chain does not break suddenly. It wears. The interface is not leaving a neutral gap. It is running a cognitive chain erosion. And that erosion is already running inside your organisation right now, invisibly, in every AI-assisted interaction your staff are having.
This is what I call cognitive chain erosion: each uncritical acceptance weakens the next judgment, which weakens the next prompt, which produces outputs that further bypass evaluation.
If your people are using AI to summarise research, synthesise feedback, or generate recommendations, and the interface produces acceptance rather than evaluation, you are not getting the return you think you are getting. You are getting speed. You are losing judgment quality, decision integrity, and over time institutional intelligence. It does not show up this quarter. It accumulates.
You need different instruments. Not replacements for what you have. Extensions into the layer they cannot see.
Trust delta: did trust increase appropriately, or lock prematurely before it was earned? Interpretive load: did the interface invite reflection, or route around it? Retention gain: did your people own what they engaged with, or skim, nod, and move on?
These are not soft metrics. They are signals of whether your AI is augmenting cognition or outsourcing it. If your evaluation cannot account for them, it is not missing a detail. It is misrepresenting the product's value to your organisation.
And cognitive chain erosion does not stay inside screens. The erosion running in your chatbot deployment today is the same erosion, at larger scale, when AI moves into the ambient systems, sensors, spatial interfaces, and physical environments your institution already operates. Public spaces, not just chat windows, are becoming AI-mediated zones. The erosion you are not yet measuring on a screen will run in a room, in a building, across an entire service environment, if you do not build the instruments now.
Until you measure thinking, not just output, you are not measuring the experience. You are measuring a proxy for it while the real effects accumulate invisibly.